[TOC]
Pandas方法
使用pandas首先要导入pandas包。
import pandas as pd //标准的导入pandas的代码读入csv文件
trainData = pd.read_csv("./Data/train.csv") //
./Data/ 表示路径,train表示文件名标题获取文件中的前5行数据
trainData.head() //
.head()是pandas中的一个方法,可以获取文件中的前5行数据
info() 迅速获取数据描述
trainData.info() // 方法就不具体介绍了 下面给出运行结果
////////////// 运行结果
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 10 columns):
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(3), object(5)
memory usage: 69.7+ KB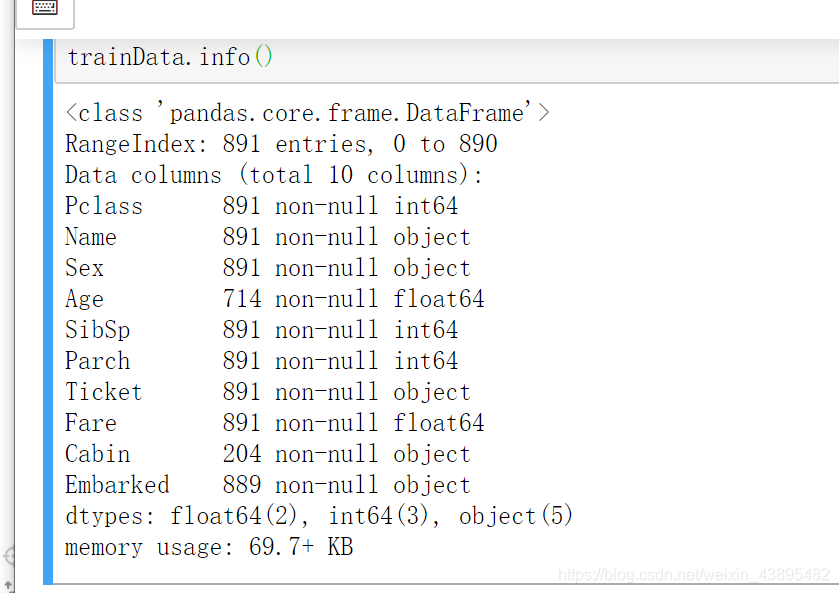
.drop( , , )
#删除name
allData.drop("Name",axis=1,inplace=True) //
第一个参数为要删除的内容,第二第三个参数的形式固定替换文件中的内容
#可以考虑替换为出现的次数
allData['SibSp'].value_counts() //
替换SibSp中缺失的数据为出现的次数
///////////////运行结果
0 891
1 319
2 42
4 22
3 20
8 9
5 6
Name: SibSp, dtype: int64合并两个文件中的内容
allData = pd.concat([trainData,testData],axis=0,ignore_index=True)
//第一个参数为两个文件名,第二第三个参数格式相同pd.set_option() 设置指定的值
pd.setoption('max_rows',7) //////设置最大的行数value_counts() 获取每个值出现的次数
trainData['Pclass'].value_counts()fillna() 用指定方法填充
age = trainData['Age']
age = age.fillna(0) ////将年龄用0来填充客串seaborn中的一个方法 distplot(age) 画出age的树状图
sns.distplot(age)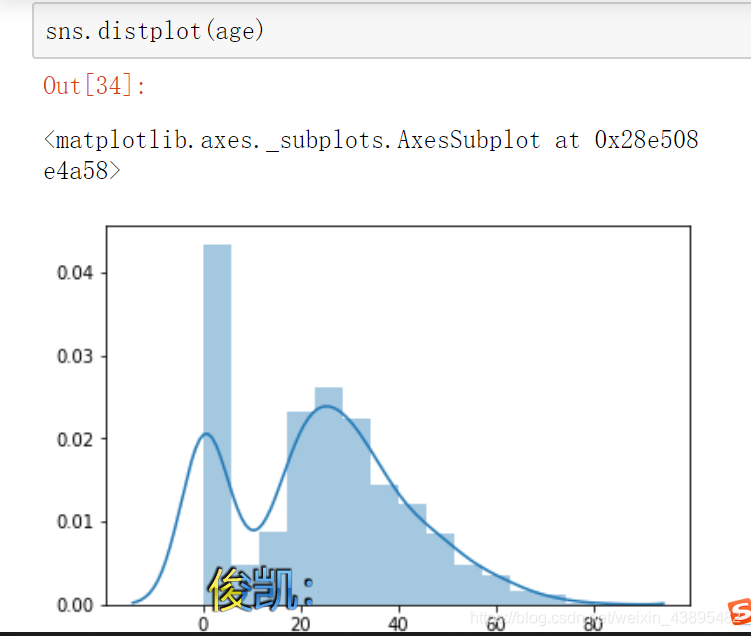
describe() 简要显示数据的数字特征
allData['Fare'].describe()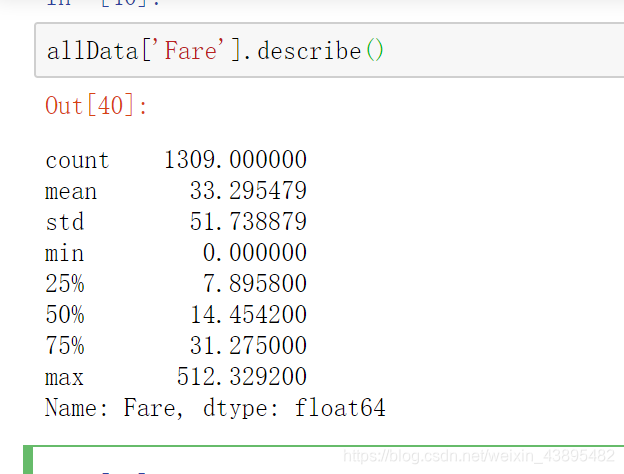
### ~corr() 计算相关系数- method:可选{‘pearson’, ‘kendall’, ‘spearman’}
- pearson: standard correlation coefficient
- kendall: Kendall Tau correlation coefficient
- spearman: Spearman rank correlation
- min_periods: Minimum number of observations required per pair of columns to have a valid result. Currently only available for pearson and spearman correlation
# 计算标准相关系数
corr_matrix = housing.corr()
corr_matrix["median_house_value"].sort_values(ascending=False)
#输出:
# median_house_value 1.000000
# median_income 0.687160
# total_rooms 0.135097
# housing_median_age 0.114110
# households 0.064506
# total_bedrooms 0.047689
# population -0.026920
# longitude -0.047432
# latitude -0.142724
# Name: median_house_value, dtype: float64


